Hey friends 👋 Welcome to a spooky new edition of Frontend at Scale. Well, it's not really that spooky. Unless you're afraid of poor grammar and questionable design decisions, in which case, get ready for one of the most terrifying experiences of your life.
This week we'll talk about readability vs. familiarity, the verdict on web components, and what a 17-year-old video game can teach us about software design.
Let's dive in.
SOFTWARE DESIGN
Intuitive Programming
Don't you just love it when you look at a piece of code and immediately understand how it works?
Or better yet, when you have to change some code and you can tell exactly where you should make the change without even thinking about it?
Or maybe you haven't noticed this at all—because that's the entire point. When code is intuitive to us, the understanding happens in an instant, without any conscious effort on our part.
What got me thinking about all of this wasn't some fancy software design book or research paper—it was Valve's 2007 classic video game, Portal. I was playing it last week in "developer commentary" mode, and I learned about a very cool technique the developers used to explain how portals worked in the game.
It turns out that many of the early playtesters initially thought that portals took you to another dimension. They had to play the game for a while before figuring out they were, in fact, just moving through different parts of the same room. So to make this mechanic clear from the beginning, the developers did something pretty clever: they positioned the very first portal of the game so that you'll inevitably see yourself on the other side of it.
They didn't have to explain how portals worked or put up a sign saying, "You're still in the same world!" when you came out the other side. The developers made the behavior of a portal completely intuitive by just putting it in the right place.
A normal person would have thought "Oh, that's smart," and continued playing the game. But you know me—I'm a massive nerd, and apparently I hate fun because instead of enjoying the amazing puzzles Portal has to offer, my head immediately started thinking about how we can use this technique to make better software design decisions.
So today I want to share with you three ways in which we can apply this principle to make our code easier to understand, both by other people and your future self. We probably can't make navigating our codebase as fun as solving puzzles with a portal gun, but we can do our best to make it as natural and intuitive as a cleverly designed video game.
Choose Good Names
You probably don't need me to tell you that naming things is very, very hard. But it's worth spending time choosing a good name because it’s the main mechanism we have for making something intuitive and easy to understand.
In The Art of Readable Code, authors Dustin Boswell and Trevor Foucher suggest that we should “pack information into our names”, meaning that we should do our best to choose names that are specific and convey meaning.
A function named getData(), for example, doesn’t pack a lot of information. In fact, it brings up more questions than answers: what exactly is this data we’re getting, and where are we getting it from? A database? Local storage? A floppy disk?
A name like fetchUserSettings(), on the other hand, packs a lot more information and immediately answers our questions: the data we’re getting are the user’s settings, and we’re fetching them from an API.
But what if the information we need to pack is just too much? After all, the reason naming is hard is that names have to do a lot of different jobs at once: they have to convey meaning and explain how something works, they have to describe the intent of the code and any side effects it might have, and, if that wasn't enough, they have to be as short as possible. When the thing we're trying to describe does many different other things, finding an intuitive name for it can be a real challenge.
In these cases—when we're really struggling to find a good name for a function, component, class, module, or even an entire system—it can be helpful to follow Arlo Belshee's advice of thinking of naming as a four-step process:
- Get to obvious nonsense: start with an honest name that describes your current understanding of the code, something like savesSomethingInTheDBIThinkAndSomeOtherStuff()
- Find what it does: describe all the things the code does, which will probably lead to a lengthy but still correct name.
- Split it into chunks: move your code around so that you only have to deal with naming one thing at a time.
- Show context: reveal the intent of the code and find the domain abstraction.
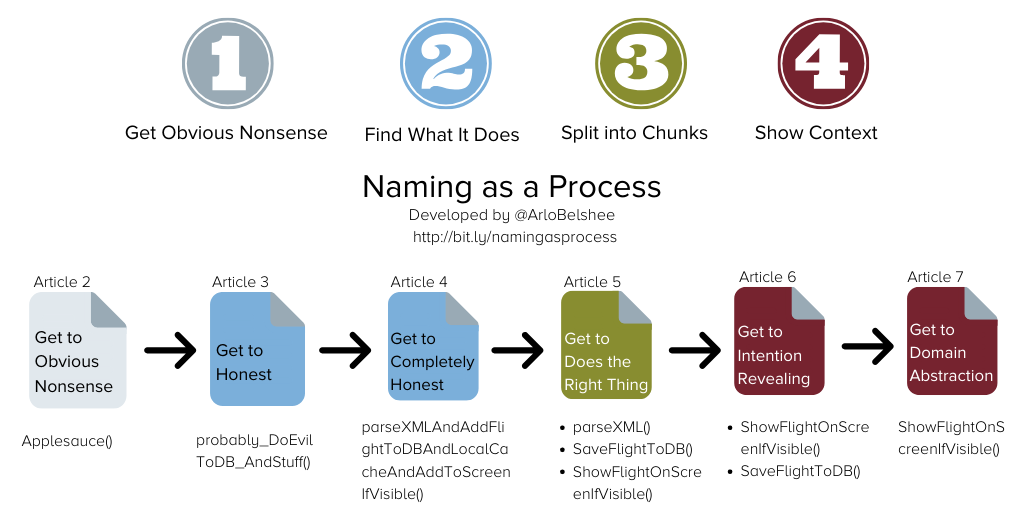
Arlo wrote a seven-part series on Naming as a Process with a detailed explanation of these steps as well as some good examples. If you prefer a video version, Emily Bache has a recorded training on YouTube that is well worth a watch.
Use Familiar Patterns
In the same way that we can pack information into our names, we can also pack a ton of information in the patterns that we use.
One of the main benefits of using classic design patterns such as Singleton, Observer, Factory, and so on is that they give us a shared vocabulary to talk about complex behaviors.
For instance, if you’re browsing through your codebase and you stumble upon a block of code that uses the Pub/Sub pattern, you’ll immediately understand a number of things about the code around it: there are going to be some publishers and subscribers somewhere, there might be some sort of message broker between them, and they’ll all talk to each other by sending events.
When a pattern is familiar to us, its behavior is intuitive—we don’t have to read a comment or README file to understand how it works, just like how Portal players don’t have to read a manual to understand that portals don’t take you to another dimension.
The key word here is familiar, of course—after all, not all of us are familiar with the same things. With patterns, there's always a learning process that needs to happen when you encounter them for the first time, but once you incorporate them, you can apply them intuitively forever.
Even if you never use classic OOP patterns (which is probably the case for those of us writing UI components all day), you can take advantage of this principle by sticking to commonly used patterns within your own codebases.
For example, I bet you can tell what the snippet below does by just glancing at it, even when it uses poor variable names like a and b and does weird things like subtracting the user's ages.
You can tell that this code is sorting an array of user objects from youngest to oldest because you've seen this pattern a million times before—it became familiar.
This also applies to patterns that might be specific to your team. For example, one pattern that used to be pretty common in my team's codebases was what we called “maybe operations”, which are functions that may or may not perform an action depending on some asynchronous condition (like checking user permissions via an API call.) So if we saw a function called maybeSendEmail() for instance, we immediately knew a few things about it:
- The email may or may not be sent as a result of calling this function,
- The function is asynchronous and returns a promise,
- The promise resolves to either true or false depending on whether the action happened or not.
It’s certainly not a perfect pattern, and we don't even use it that often these days, but it worked for our team as long as we applied it consistently.
And that's the good thing about this principle; the patterns don't even need to be good ones to take advantage of it. As long as they're familiar to us, sticking to them will certainly make our code much more intuitive.
Represent Logic As Data
In Grokking Simplicity, Eric Normand talks about how functional programmers always classify code into three categories: actions, calculations, and data:
- Actions depend on when they’re called or how many times they’re called. Think of a sendEmail() or getCurrentTime() function.
- Calculations are computations from inputs to outputs, and they always behave the same no matter when or how many times they’re called. For instance, a sum() function.
- Data is… well, just data—facts about recorded events. Think of an array of numbers or an object with a user’s first and last name.
This distinction is important because, in general, data is easier to deal with than calculations, and calculations are easier to deal with than actions. Data is more intuitive and easier to manipulate than logic, so, if we can find a way to represent something as data, we probably should.
A simple example of this principle in JavaScript is replacing a switch statement with an object literal. But we can also use it for more complex use cases, like when the data and rules of our code are deeply intertwined.
I give an example of this in my talk The Messy Middle when I talk about reducing cognitive load. You can watch it for the full explanation, but the short version is this: when the logic is too complex, instead of looking to replace it with data, we can try to encapsulate it and expose its rules via a simple data structure.
Another way in which we can use data to make something more intuitive is when we use data structures that are more specific and communicate intent.
For example, can you guess what the difference between these three arrays is?
That was a bit of a trick question. There is no real difference here, they’re just three arrays.
But what about now?
Aha! Now the data structures reveal much more information. We know that the first one doesn’t have repeated values and that the other two are intended to behave as stacks and queues respectively, so the order of the elements is important and we’ll be doing a lot of pushing and popping but not grabbing elements from the middle.
That was a mouthful, but you didn't need me to tell you any of that. All of that information was immediately available to you just because we chose more specific data structures. And just like choosing a good name, choosing a good way to represent our data can make our code not just more intuitive, but just generally more enjoyable to work with.
Earlier I mentioned that intuitive programming can help you grasp the essence of a piece of code without having to read comments. This is not an anti-comment article, though. I think comments are great, and I think they’re sometimes even necessary.
But while comments can turn a hard-to-understand concept into an easy-to-understand one, intuitive code goes one step further, making the understanding almost instantaneous.
Why does this matter? You might recall that in an earlier issue, we defined software complexity as anything that makes a system hard to change or hard to understand. So by making our code more intuitive, we're not just saving the few seconds it takes to read a comment here and there. We're accomplishing something much deeper—we're attacking complexity directly at its core.
ARCHITECTURE SNACKS
Links Worth Checking Out
- The topic of familiar patterns in today's essay was inspired by Cory Brown's talk Don't confuse Readability with Familiarity, which I had the pleasure of watching live at UtahJS last month. I very much enjoyed Corey's talk—it's a fun watch and a great introduction to the concept of readability in software design.
- People on the internet have been fighting about web components if you can believe it! We're late to this party (as usual), but I didn't want to miss the opportunity to share Nolan Lawson's article on the topic because, also as usual, he has the more nuanced takes.
- ViteConf 2024 was last week, and if you missed any of its 43 talks, you can now binge-watch the entire replay on their website. It'll only take you 30 minutes if you watch it at 24x speed (or 12 hours at 1x)
- If you only have one hour to spare, you can watch the comparatively short Deno 2.0 announcement, which features one of the funniest and best-produced intros you've ever seen for an open-source project.
- From the creators of clientless clients and networkless networks, Vercel introduced serveless servers, a feature that lets a single serverless function handle multiple calls concurrently. So it's like a regular server, but still serverless. I hope that clears things up.
- Blake Watson wrote HTML for People, a free book that can teach anyone to build websites with HTML and just a bit of CSS. You're all probably too experienced for this book, but it's a good resource to share with anyone who might be interested in getting started building websites with code.
- Sam Selikoff wrote an interactive tutorial that teaches us how to build React components using the browser's native state management mechanism, the URL.
- This software architecture reading list just made my Amazon wishlist a lot bigger.
- Amelia Wattenberger wrote about how user interfaces help us bridge the gap between the hard world of machines and the soft world of humans.
- It's hard to write code for computers, but it's even harder to write code for humans. That's Erik Bernhardsson on the challenges of writing libraries, frameworks, and programming languages.
That’s all for today, friends! Thank you for making it all the way to the end. If you enjoyed the newsletter, it would mean the world to me if you’d share it with your friends and coworkers. (And if you didn't enjoy it, why not share it with an enemy?)
Did someone forward this to you? First of all, tell them how awesome they are, and then consider subscribing to the newsletter to get the next issue right in your inbox.
I read and reply to all of your comments. Feel free to reach out on Twitter, LinkedIn, or reply to this email directly with any feedback or questions.
Have a great week 👋
– Maxi
