Hey friends 👋 Happy last day of March, and for all the business folks in the audience, happy last day of Q1-2024! I hope you all crushed your OKRs, OGSMs, KPIs, and OMGs for this cycle.
Also, remember that tomorrow is April Fools’ Day so double and triple-check everything you read online. Unless you’re reading this newsletter on April Fools, in which case you can trust that everything you read here is 100% real… or is it?? (yes, it is.)
This week we'll talk about rewrites, modernizing legacy codebases, and the beautiful simplicity of Action Script 3.0. Let’s jump in!
SOFTWARE DESIGN
Fantastic Rewrites and How to Avoid Them
Sometimes I sit at my computer, open my code editor, look at my messy code, cry a little, and think about how much better things would be if I could rewrite my app from scratch.
And by sometimes, I mean roughly every other day.
But big rewrites are risky and expensive, and they have a reputation for almost certainly being a bad idea.
So bad in fact, that Joel Spolsky famously called them “the single worst strategic mistake that any software company can make.” That’s right, even worse than naming your company after a single letter of the alphabet.
And yet, sometimes rewrites feel necessary. Legacy codebases can become so difficult to maintain that they end up driving progress and innovation to a halt. When features start to take forever to ship, it can seem that the only way forward is to start from scratch.
Fortunately, there’s plenty of room in the middle, and there are ways in which we can modernize our codebase without the risks and costs of a big-bang rewrite.
We’ll talk about those in a minute, but first, let me tell you a story about how a young and curly-haired Maxi learned (the hard way, of course) why big rewrites tend to fail.
A Cautionary Tale
We all experience a failed rewrite or two (or ten) at some point in our careers. In my case, I was fortunate to experience my first massive failure pretty early on.
As a young web developer in the late 2000s, I worked for a small software shop maintaining a web invoicing application similar to (but not as pretty as) Freshbooks. I had a lot of fun at this job, but working on this application wasn’t always the best experience.
The codebase was a typical case of a big ball of mud architecture—a pile of PHP and jQuery spaghetti code that was becoming harder to change every day. So, of course, I did what I thought was the only reasonable option at the time, and I proposed a rewrite of the entire application using one of the hottest technologies around: Adobe Flex.
Armed with all the energy and free time that only a 20-year-old can have, I built a proof-of-concept that had about 50% of the features of the real product in the span of a week. It looked absolutely gorgeous, and the codebase was a beautiful specimen of the cleanest Action Script 3.0 code you’ve ever seen.
My boss loved my prototype and asked me how long it would take to build the real thing. A little estimation exercise told me that, if it took me a week to get to 50%, it should take me another week to get to 100% (I’m very good at math as you can see.) I said two weeks to be safe, and they gave me the green light to attempt my rewrite.
Any reasonable tech lead or experienced engineer would have stopped me right there and asked me a million questions before deciding to take on this project. But unfortunately I didn’t have one of those, so I charged on with my rewrite full of dreams and hopes for the future.
Here’s how the rewrite was supposed to go:
Compared to the status quo (i.e. living with the legacy codebase), my rewrite would cause an initial slowdown in the number of features we shipped, but it would end up paying off big time in the long run given how easy it would be to add new features to the new codebase.
With this model, the tradeoff makes total sense. The rewrite has costs and benefits, but the benefits drastically outweigh its costs. It was an easy call to make.
Of course, that’s not how things went at all.
Two weeks turned into four, four weeks into two months, and when it was clear the product would never be production-ready, we had to shut it down. My beautiful Flex invoicing app never saw the light of day.
This is a far too common tale, and I’m sure you’ve faced a similar situation at some point. When it comes to rewrites (especially the big, messy ones), we tend to underestimate both the complexity of the product’s features and the amount of work necessary to handle all the little details that hide under the surface.
If we think about why the legacy codebase grew so messy over time, we’ll find that it was because it had to change in unexpected ways to account for all these little details. Here’s how Joel Spolsky puts it in his seminal essay:
“Back to that [big messy] function. Yes, I know, it’s just a simple function to display a window, but it has grown little hairs and stuff on it and nobody knows why. Well, I’ll tell you why: those are bug fixes. One of them fixes that bug that Nancy had when she tried to install the thing on a computer that didn’t have Internet Explorer. Another one fixes that bug that occurs in low memory conditions. Another one fixes that bug that occurred when the file is on a floppy disk and the user yanks out the disk in the middle. That LoadLibrary call is ugly but it makes the code work on old versions of Windows 95.Each of these bugs took weeks of real-world usage before they were found. […] When you throw away code and start from scratch, you are throwing away all that knowledge. All those collected bug fixes. Years of programming work.”
Not all rewrites fail to ship, of course—I’ve had the fortune of working on some successful rewrites since my Flex app experience. While it is common for rewrites to ship later than originally expected, it is also common to see them delivering on the promise of improved developer experience and cycle time.
So I don’t think “never rewrite” is good advice either. After all, the pains that developers feel with a legacy codebase are real, and failing to modernize it could be a mistake as big as attempting to rewrite the entire thing from scratch.
It is the “from scratch” part that we need to be careful about. Full rewrites are tempting because they promise to relieve our apps from the burdens of a legacy system. No more messy code to maintain—just a clean slate.
But I think trying to start from scratch is a mistake. Instead, we can give our rewrite the best chance of success—and ourselves a much easier time—if we just start from where we are.
Start Where You Are
What we often get wrong about rewrites is that we look past the legacy codebase we have today instead of using it as a foundation for the next version of the application.
Sure, greenfield projects are much more fun to work on, but the larger the codebase we’re trying to modernize is, the riskier it is to start from scratch.
By using the legacy codebase as a starting point instead, we can create a strategy that allows us to modernize it while continuing to ship business value at the same time.
In Patterns for Legacy Displacement, authors Ian Cartwright, Rob Horn, and James Lewis share a simple but powerful framework for dealing with these scenarios. It consists of four steps:
- Understand the outcomes you want to achieve
- Decide how to break the problem up into smaller parts
- Successfully deliver the parts
- Change the organization to allow this to happen on an ongoing basis
Let’s talk about each one in more detail.
1. Understand the outcomes you want to achieve
When we talk about rewrites, we typically start with the reasons why we think it’s necessary: the codebase is too messy, the technology is too old, we’re not moving fast enough, and so on.
These are all valid reasons, but they can tunnel our vision and make us believe that a rewrite is the only solution available.
Instead, we should focus on the outcomes we want to achieve and articulate as clearly as possible why it’s important that we achieve them. If we define the outcome to improve the “cost of change” of a system, for example, we might find that there are a number of ways in which we can achieve it—a full rewrite being only one of them.
Understanding the outcomes also helps to prevent attempting rewrites for the wrong reasons. Rewriting our Laravel app with Next.js would make sense if we have reason to believe it will improve productivity, for example. But if the outcome we're trying to achieve is "use the framework everyone on Twitter seems to be using", we probably have more thinking to do.
2. Decide how to break the problem up into smaller parts
Modernizing a legacy codebase is a massive challenge, so it’s key that we break it down into smaller parts that are easier to reason about.
This involves finding the right “seams” in the current system, which can sometimes be a big challenge in and of itself. Chances are that our system (especially if it’s a big monolithic one) is doing more than one job, spanning multiple domains, and being maintained by multiple teams. All of these are opportunities to find seams in the system that would allow us to break it down into smaller chunks.
For frontend applications, a good place to start is by breaking things down into modules or top-level routes. And if a module is too big, we could further break it down into sub-modules or components.
3. Successfully deliver the parts
Once we’ve identified the parts, we need to figure out how we’re going to deliver them incrementally rather than all at once.
A popular method to do this is by using the strangler pattern—which I recently learned it’s named after the strangler fig tree; not the Scranton Strangler from The Office.
With the strangler pattern, we can incrementally replace a legacy system with a new one by shipping its pieces one at a time. This pattern is typically used when moving from a monolith to micro-services, but we can use it anytime we need to modernize a large application in an incremental fashion.
In frontend applications, adopting a micro-frontends architecture is one effective way to deliver the parts, but it’s not the only one. Using a framework like Astro is a great way to incrementally migrate a codebase from one framework to another, for instance. Or we could use something like Remix SPA Mode to slowly transform an existing SPA into a server-side rendered app.
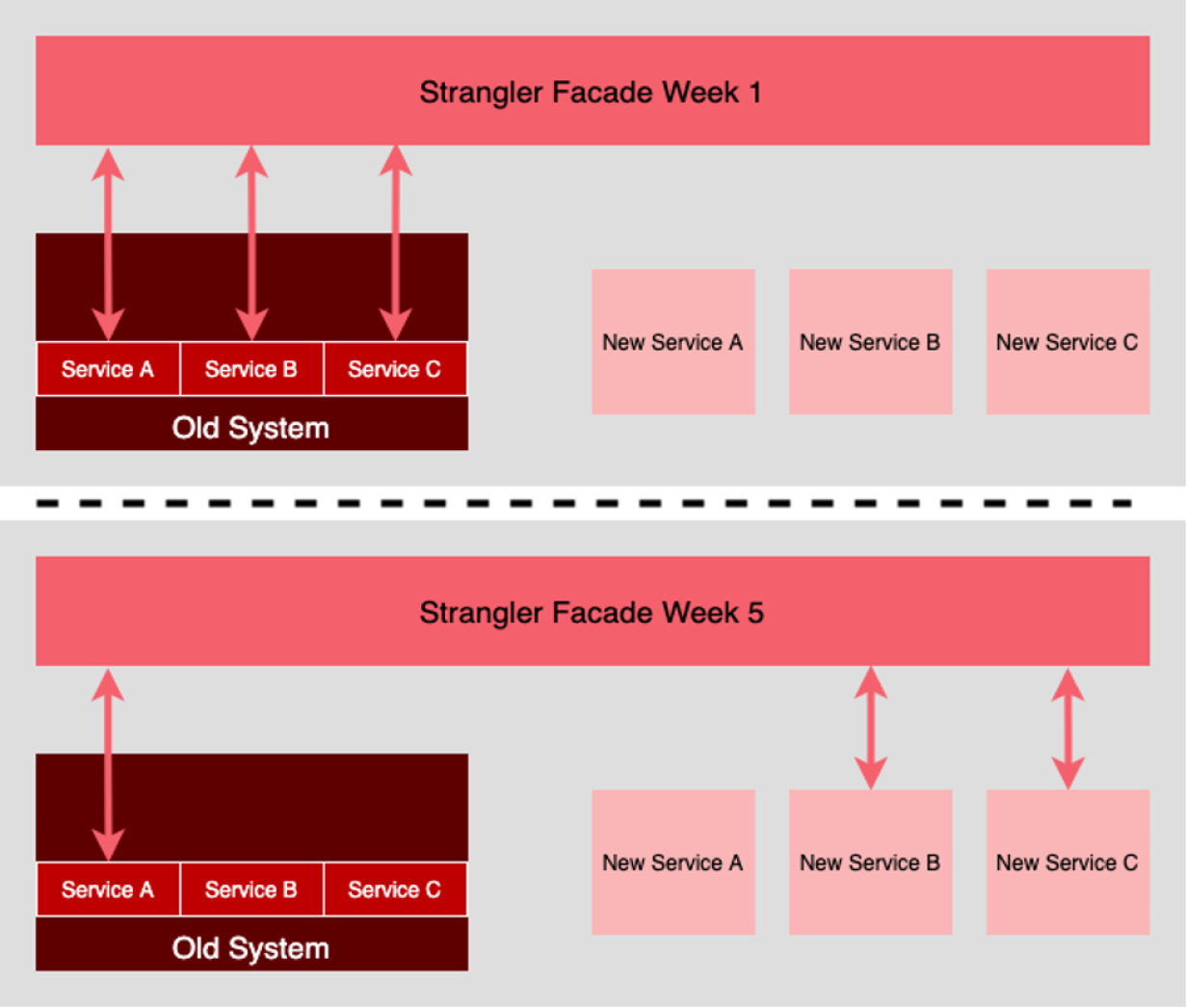
4. Change the organization to allow this to happen on an ongoing basis
Finally, if we want to break the cycle of attempting a rewrite every five years, we need to adopt a mindset of ongoing codebase modernization while continuing to deliver value to customers.
This is the hardest of the four steps, but if we don’t make an effort to maintain our system design and handle technical debt on an ongoing basis, it’s only a matter of time before the next rewrite becomes necessary.
Every software company needs to find ways to modernize its technology while continuing to ship business value. This is a massive challenge for any organization, but adopting a framework like this one can help us achieve this modernization in a more sustainable and incremental way.
A while ago, we talked about this article about refactoring by German Velasco, and its title has been stuck in my head ever since:
Refactoring has a price. Not refactoring has a cost. Either way, you pay.
We can say the same thing about rewrites.
Big rewrites are expensive. There is of course the monetary cost of all the hours developers have to spend working on them, but there’s also the opportunity cost of all the things they could have worked on instead.
Deciding not to rewrite a legacy codebase can be costly as well. We pay it in decreased productivity and developer unhappiness. And just like 3-bedroom houses in California, it only tends to get more expensive over time.
Either way, we have to pay. But how much we pay depends largely on the approach we take to modernizing our codebase.
If we start from where we are, break things down into pieces, and rewrite them incrementally, we can make sure that however much we end up paying, it is at least a fair price.
ARCHITECTURE SNACKS
Links Worth Checking Out
📕 READ
- If Devin still haunts your dreams even after reading the previous issue of Frontend at Scale, this article by Murat Demirbas should help keep those dystopian AI nightmares at bay.
- Chris Coyier wrote a comprehensive and bookmarkable guide with everything you need to know about modern CSS. I heard he knows a thing or two about this stuff.
- The RxDB docs site has a great article explaining the differences between web sockets, server-sent-events, WebTransport, pigeon post, and the many other ways to do real-time these days.
- For all the React fans out there getting tired of people criticizing their favorite framework, this article by Joshua Johanan on why he still likes React in 2024 should be a refreshing read.
🎥 WATCH
Durable Objects - Everything Everywhere All At Once For Not Very Much Money by Jani Eväkallio
For not very much money, you say? That’s perfect because that’s exactly how much money I’ve got! Durable Objects is a really cool technology from Cloudflare that lets us build collaborative editing tools (think Figma or Google Docs), chats, multiplayer games, and other apps that require reliable coordination of shared state. And like most things from Cloudflare, it’s really inexpensive. This was a fun talk explaining how Durable Objects work in simple terms and via a series of really cool live-coding demos.
🎧 LISTEN
At the bar with Whiskey Web & Whatnot with Robbie Wagner and Chuck Carpenter
I enjoyed this special crossover episode of the Front End Happy Hour podcast with the hosts of Whiskey Web and Whatnot. It was a fun conversation about AI, AR, VR, Vision Pro, and I think a bit of web development as well. Definitely listen while drinking your favorite adult beverage.
That’s all for today, friends! Thank you for making it all the way to the end. If you enjoyed the newsletter, it would mean the world to me if you’d share it with your friends and coworkers. (And if you didn't enjoy it, why not share it with an enemy?)
Did someone forward this to you? First of all, tell them how awesome they are, and then consider subscribing to the newsletter to get the next issue right in your inbox.
I read and reply to all of your comments. Feel free to reach out on Twitter or reply to this email directly with any feedback or questions.
Have a great week 👋
– Maxi
